재귀
재귀의 개념
재귀는 함수의 정의 내부에서 스스로를 사용하는 함수를 정의하는 방법을 의미합니다. 수학에서의 정의들은 재귀를 자주 사용합니다. 수학적 정의에서 재귀가 사용되는 대표적인 예로 피보나치 수열을 들 수 있습니다. 피보나치 수열은 재귀적이지 않은 첫번째 두번째 피보나치 숫자부터 시작됩니다.
F\(0\)=0, F\(1\)=1은 피보나치 수열의 첫번째 값은 0이고, 두번째값을 1임을 의미하고, 세번째 값부터는 이전의 값 두개의 합입니다. 따라서 F(n) = F(n-1) + F(n-2)와 같이 정의할 수 있습니다. 따라서 F(3)은 F(2) + F(1)이고, 이것은 (F(1) + F(0)) + F(1)로 전개됩니다.
재귀에서 F(0)과 F(1)과 같이 재귀적이지 않은 방법으로 정의되는 한개 또는 두개의 구성 요소를 edge condition이라고 부릅니다. edge condition은 재귀를 끝내기 위해서 반드시 필요한 매우 중요한 개념입니다. 만약 피보나치 예제에서 F(0)과 f(1)을 재귀적이지 않게 정의하지 않으면, 음수가 나오고도 끝나지않고 계속해서 자기자신을 호출하게 됩니다.
명령형 언어와 달리 하스켈에서는 재귀가 매우 중요합니다. 하스켈에서는 어떻게(how you get it) 값을 계산할 수 있을지를 선언하는 대신 무엇을(what something) 선언할지를 고민해야합니다. 무엇을 선언할지를 결정할때 재귀가 많이 사용되어야 하고, 이것이 하스켈에 while과 for같은 루프가 없는 이유입니다.
재귀 함수 예제
Maximum 함수
maximum은 순서가 있는(Ord typeclass) 아이템들의 리스트를 받아서 가장 큰 아이템을 돌려주는 함수입니다.
이 함수를 만약 명령형 언어로 구현한다면 어떻게 할 수 있을까요? 아마도 최대값을 선언해놓고 모든 구성 요소들을 순회하면서 현재 최대값보다 크면 값을 업데이트하여 마지막에 남은 값을 최대값을 리턴할 것 입니다. 이런 방법은 아주 간단한 알고리즘 표현하는데도 많은 코드를 사용하게 됩니다.
동일한 함수를 재귀적으로 정의하면 어떻게 될까요? 먼저 종료 조건(edge conditon)의 정의하고 아이템이 한개인 경우와 리스트인 경우에 대해서 정의합니다. 만약 tail의 최대값보다 head가 더 크다면 head가 리스트의 최대값이라고 할 수 있고, 반대의 경우 tail의 최대값이 리스트의 최대값이 됩니다. 이제 아래와 같이 하스켈로 구현하면 됩니다.
maximum' :: (Ord a) => [a] -> a
maximum' [] = error "maximum of empty list"
maximum' [x] = x
maximum' (x:xs)
| x > maxTail = x
| otherwise = maxTail
where maxTail = maximum' xs
재귀를 구현하기 위해서 패턴매칭을 사용한 것을 볼 수 있습니다. 대부분의 명령형 언어는 패턴매칭을 지원하지 않아서 많은 if else 구문을 사용해서 구현해야 합니다.
첫번째 패턴은 종료조건(edge condition)으로 빈리스트가 들어온 경우입니다. 빈리스트에서는 최대값을 구할 수 없기 때문에 에러로 처리되었습니다.
두번째 패턴은 값이 한개인 리스트입니다. 따라서 리스트에 포함된 한 개의 값이 최대값입니다.
세번째 패턴에서는 리스트를 head와 tail로 분리하기 위해서 패턴매칭을 사용하였습니다. 이것은 재귀를 사용할 때 자주 사용되는 방식입니다. where 바인딩에서는 나머지 리스트의 최대값을 구하는 maxTail 함수를 정의하였습니다. 그리고 나서 maxTail을 사용해서 head값이 리스트의 나머지 값의 최대값보다 큰지 체크하여 큰 것을 리턴합니다.
위의 함수가 [2,5,1]에 대해서 수행하는 과정을 보면 아래와 같습니다.
- maximum’ [2,5,1]이 세번째 패턴에 매칭되어 2와 [5,1]이 분리됩니다.
- where절에서는 maximum [5,1]로 최대값을 구합니다.
- maximum [5,1]이 세번째 패턴에 매칭되어, 5와 [1]로 분리됩니다.
- 다시 where에서는 maximum [1]로 최대값을 구합니다.
- maximum [1]이 종료조건인 두번째 패턴에 매칭되어, 1을 리턴합니다.
- 4단계의 결과가 1, 2단계의 결과가 5, 3단계의 결과로 다시 5가 되어 최종적으로 5가 리턴됩니다.
maximum' :: (Ord a) => [a] -> a
maximum' [] = error "maximum of empty list"
maximum' [x] = x
maximum' (x:xs) = max x (maximum' xs)
max 함수를 사용하면 위와 같이 좀 더 깔끔한 방법으로 구현할 수 있습니다. 본질적으로 리스트의 최대값은 첫번째 요소의 최대값과 나머지 요소들의 최대값이 됩니다.
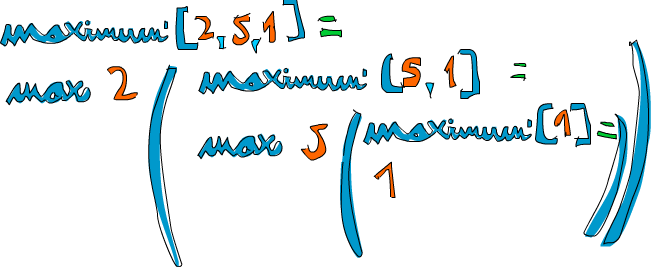
Replicate 함수
replicate 함수는 Int값(n)과 어떤 요소(x)를 입력받아, x를 n개만큼 가지고 있는 리스트를 반환하는 함수 입니다. 예를들어 replicate 3 5를 호출하면 [5,5,5]를 리턴합니다. 먼저 종료조건을 생각해보면 n이 0보다 작거나 같으면, 빈 리스트를 반환해야 하는 것을 생각할 수 있습니다.
replicate' :: (Num i, Ord i) => i -> a -> [a]
replicate' n x
| n <= 0 = []
| otherwise = x:replicate' (n-1) x
이 예제에서는 boolean 조건 테스팅을 위해서 패턴매칭 대신 가드를 사용하였습니다. 따라서 n이 0보다 작거나 같으면 빈리스트를 리턴합니다. n이 0보다 크면 첫번째 요소로 x를 가지고 나머지 꼬리에서 n-1번 replicate을 수행합니다. 결국 (n-1) 부분이 종료조건(edge condition)까지 갈 수 있는 이유가 됩니다.
위 예제에서
Num은Ord의 서브클래스가 아닙니다. 따라서Num과Ord를 둘다 명시해야 함수 내부에서 덧셈, 뺄셈 또는 비교가 가능한 입력으로 제한할 수 있습니다.
take 함수
take 함수는 리스트로부터 구성요소들의 개수는 만큼만 가져옵니다. 예를들어 take 3 [5,4,3,2,1]을 호출하면 [5,4,3]을 리턴합니다. 만약 0이나 0 이하의 구성요소를 꺼내려고 하면 빈 리스트를 리턴합니다. 또한 빈 리스트로부터 무엇이든 꺼내려고 하면 빈 리스트를 리턴합니다. 이 두가지 조건이 종료 조건이 됩니다.
take' :: (Num i, Ord i) => i -> [a] -> [a]
take' n _
| n <= 0 = []
take' _ [] = []
take' n (x:xs) = x : take' (n-1) xs
첫번째 패턴은 n이 0이나 0보다 작은 경우 빈 리스트를 리턴하였습니다. _는 무엇이든 상관하지 않겠다는 의미이기 때문에 리스트에 매칭되고, otherwise없는 가드를 사용하여 만약 n이 0보다 크면 다음 패턴에 매칭되도록 하였습니다.
두번째 패턴에서는 빈 리스트에서 구성요소를 꺼내려고 할때 항상 빈 리스트를 리턴하도록 하였습니다.
세번째 패턴은 입력 리스트를 head와 tail로 분리하고, 리스트에 head를 포함시키고 tail은 n-1로 다시 take를 재귀호출 하였습니다.
reverse 함수
reverse 함수는 간단하게 입력으로 들어온 리스트의 구성요소를 뒤짚는 함수입니다.
reverse' :: [a] -> [a]
reverse' [] = []
reverse' (x:xs) = reverse' xs ++ [x]
빈 리스트가 들어오면 뒤짚어도 빈 리스트이기 때문에 종료조건입니다. 그 다음에 head와 tail을 분리하여 거꾸로 뒤짚어서 재귀호출하면 리스트가 뒤짚어진다는 것을 쉽게 생각할 수 있습니다.
repeat 함수
하스켈을 무한 리스트를 지원하기 때문에 종료조건(edge condition)이 없어도 되지만, 없으면 무한하게 동작하거나 무한한 자료구조를 만들게 됩니다. 무한한 리스트의 좋은 점은 우리가 원하는 곳에서 잘라낼 수 있다는 점입니다. repeat 함수는 입력 요소의 무한한 목록을 반환하는데, 재귀 구현이 간단합니다.
repeat' :: a -> [a]
repeat' x = x:repeat' x
만약 repeat 3을 호출하면 아래와 같이 무한하게 반복 호출되어 끝나지 않을 것입니다.
repeat 3
3:repeat 3
3:(3:repeat 3)
3:(3:(3:repeat 3)
...
반면에 take 5 (repeat 3)를 사용하면 replicate 5 3을 호출한 것과 같은 결과를 얻을 수 있습니다.
zip 함수
zip 함수는 두개의 리스트를 받아서 합치는 함수입니다. zip [1,2,3] [2,3]을 호출하면 [(1,2), (2,3)]을 반환합니다. 왜냐하면 두개의 리스트 중, 길이 작은 리스트를 기준으로 잘라내기 때문입니다. 따라서 두개의 리스트중 빈 리스트가 하나라도 들어오면 빈 리스트를 반환하고 이것을 종료조건으로 사용할 수 있습니다.
zip' :: [a] -> [b] -> [(a,b)]
zip' _ [] = []
zip' [] _ = []
zip' (x:xs) (y:ys) = (x,y):zip' xs ys
처음 두개의 패턴은 두개의 입력 리스트 중, 빈 리스트가 있으면 빈 리스트를 반환하여 끝내는 종료조건 입니다.
세번째 패턴은 두개의 리스트의 각 head를 묶어 첫번째 튜플을 만들고, 각 tail을 사용하여 재귀호출 하였습니다.
[1,2,3]과 ['a', 'b']를 입력으로 호출하면 마지막에 zip [3] [] 호출되게 될 것입니다. 이것은 종료조건에 매칭되어 최종적으로 (1,'a'):(2,'b'):[]가 되는데 이것은 [(1,'a'),(2,'b')]와 동일합니다.
elem 함수
elem 함수는 입력값이 입력 리스트에 존재하는 검사합니다.
elem' :: (Eq a) => a -> [a] -> Bool
elem' a [] = Flase
elem' a (x:xs)
| a == x = True
| otherwise = a `elem'` xs
입력 리스트가 빈 리스트이면 입력값을 당연히 존재하지 않기때문에 종료조건으로 사용됩니다.
만약 입력 리스트의 head가 입력값이 아니면 tail을 가지고 다시 한번 검사합니다. 만약 빈 리스트에 도달하면 입력값이 없는 것이므로 결과는 False입니다.
quicksort 함수
정렬 가능한 리스트의 아이템 타입클래스는 Ord 입니다. quicksort 함수는 정렬 가능한 리스트의 구성요소를 정렬하는 알고리즘입니다. 명령형 언어를 사용해서 구현하면 적어도 10라인 이상의 코드로 quicksort 구현이 가능하지만 하스켈을 사용하면 보다 간결하게 할 수 있습니다.
quicksort 알고리즘은 임의의 값(Pivot)을 기준으로 앞에는 값이 작은 모든 원소가 오고, 뒤에는 값이 큰 모든 원소가 오도록 분할하고, 분할된 두 개의 작은 리스트에 대해서 리스트의 크기가 0이나 1이 될때까지 재귀적으로 이 과정을 반복하여 정렬하는 알고리즘 입니다.
빈리스트는 정렬하면 빈리스트이므로 쉽게 종료조건으로 사용될 수 있습니다. quicksort 알고리즘의 정의에서 언급한 두개의 리스트를 두번의 재귀 호출이 필요함을 의미합니다. 알고리즘을 정의하기 위해서 해야할 일들을 나열하지 않고, 동사를 사용하여 정의하였는데, 이것이 함수형 프로그래밍의 특징입니다. 리스트에서 임의의 값보다 작은 것들과 큰 것들로 분할하려면 List Comprehensions을 활용할 수 있습니다.
quicksort :: (Ord a) => [a] -> [a]
quicksort [] = []
quicksort (x:xs) =
let smallerSorted = quicksort [a | a <- xs, a <= x]
biggerSorted = quicksort [a | a <- xs, a > x]
in smallerSorted ++ [x] ++ biggerSorted
아래는 quicksort 함수를 테스트해본 것입니다.
ghci> quicksort [10,2,5,3,1,6,7,4,2,3,4,8,9]
[1,2,2,3,3,4,4,5,6,7,8,9,10]
ghci> quicksort "the quick brown fox jumps over the lazy dog"
" abcdeeefghhijklmnoooopqrrsttuuvwxyz"
만약 [5,1,9,4,6,7,3]을 입력으로 준다면 아래와 같은 순서로 동작할 것 입니다.
[5,1,9,4,6,7,3]
[1,4,3] ++ [5] ++ [9,6,7]
([] ++ [1] ++ [4,3]) ++ [5] ++ ([6,7] ++ [9] ++ [])
([] ++ [1] ++ ([3] ++ [4])) ++ [5] ++ (([] ++ [6] ++ [7]) ++ [9] ++ [])
[] ++ [1] ++ [3] ++ [4] ++ [5] ++ [] ++ [6] ++ [7] ++ [9] ++ []
[1,3,4,5,6,7,9]
재귀적 사고
재귀를 활용하여 구현한 여러가지 예제에서 보았듯이 여기에는 패턴이 있습니다. 일반적으로 종료조건(edge case)를 정의한 다음, 어떤 구성요소와 나머지 요소들에 적용된 함수 사이에 동작을 정의합니다. 일반적으로 종료조건은 재귀를 할때 의미가 없는 경우이고, 리스트에서는 빈리스트가, 트리에서는 자식이 없는 노드인 경우가 이에 해당합니다. 숫자로 재귀를 할때도 마찬가지 입니다. factorial에서 0, 곱하기에서 1, 더하기에서 0은 의미가 없는 값입니다.
따라서 재귀적으로 문제를 풀때는 재귀적으로 해결되지 않는 경우를 생각하고 이것을 종료조건으로 사용할 수 있는지 생각해야 합니다. 그리고 함수의 입력을 분할(예를들어, 리스트는 일반적으로 패턴매칭을 활용하여 head와 tail로 분리함)하여 어떤 부분에서 재귀 호출을 사용할지 결정합니다.